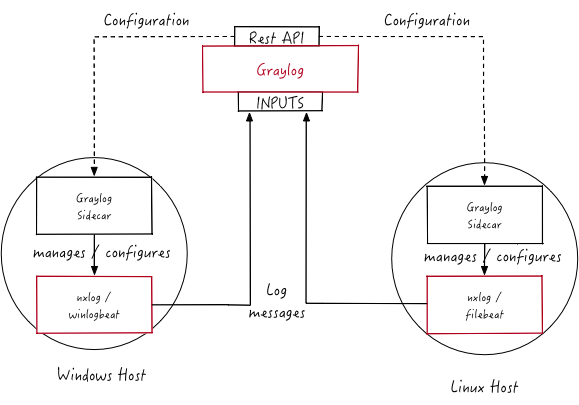
Como hemos hablado anteriormente, Graylog es un colector de logs muy interesante. Es una mezcla entre ELK y Splunk. No llega a ser tan potente como Splunk pero es mas gestionable que ELK.
En este post, voy a explicar como instalar un agente y enviar todos los logs al Graylog central. Graylog tiene un agente llamado collector-sidecar que es muy fácil de configurar y además se gestiona de un modo centralizado una vez que se despliega.
Cliente
Instalación del cliente
En este post vamos a utilizar la versión 0.1.4 para entornos debian x64 que es la mas actual. Si se quiere descargar otra, se puede hacer desde aquí.
wget https://github.com/Graylog2/collector-sidecar/releases/download/0.1.4/collector-sidecar_0.1.4-1_amd64.deb
Instalar el paquete
dpkg -i collector-sidecar_0.1.4-1_amd64.deb
Crear el servicio de arranque
graylog-collector-sidecar -service install
Configuración del cliente
Editar el archivo de configuración
vim /etc/graylog/collector-sidecar/collector_sidecar.yml
server_url: http://graylog.ichasco.com:9000/api/ update_interval: 10 tls_skip_verify: false send_status: true list_log_files: /var/log node_id: agente collector_id: file:/etc/graylog/collector-sidecar/collector-id cache_path: /var/cache/graylog/collector-sidecar log_path: /var/log/graylog/collector-sidecar log_rotation_time: 86400 log_max_age: 604800 tags: - linux backends: - name: filebeat enabled: true binary_path: /usr/bin/filebeat configuration_path: /etc/graylog/collector-sidecar/generated/filebeat.yml
Iniciar el proceso de graylog
systemctl start collector-sidecar
Servidor
Para empezar, hay que generar un Input nuevo. Para ello vamos a “System –> Inputs”
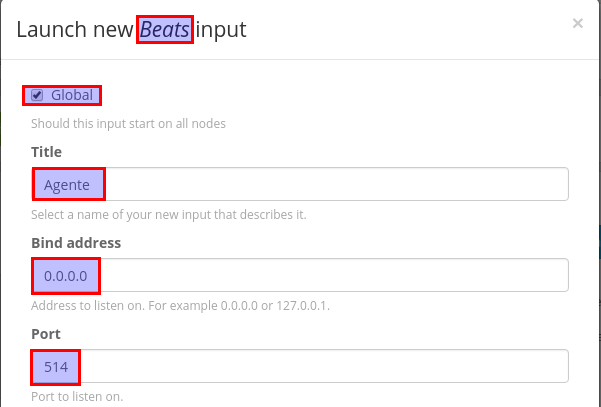
Ahora vamos a crearlo. Tiene que ser del formato Beats.
Una vez añadido el input, hay que configurar el colector. Para ello “System –> Collector”
Ahora, vamos a gestionar las configuraciones
![]()
Y creamos la configuración para el nuevo colector
![]()
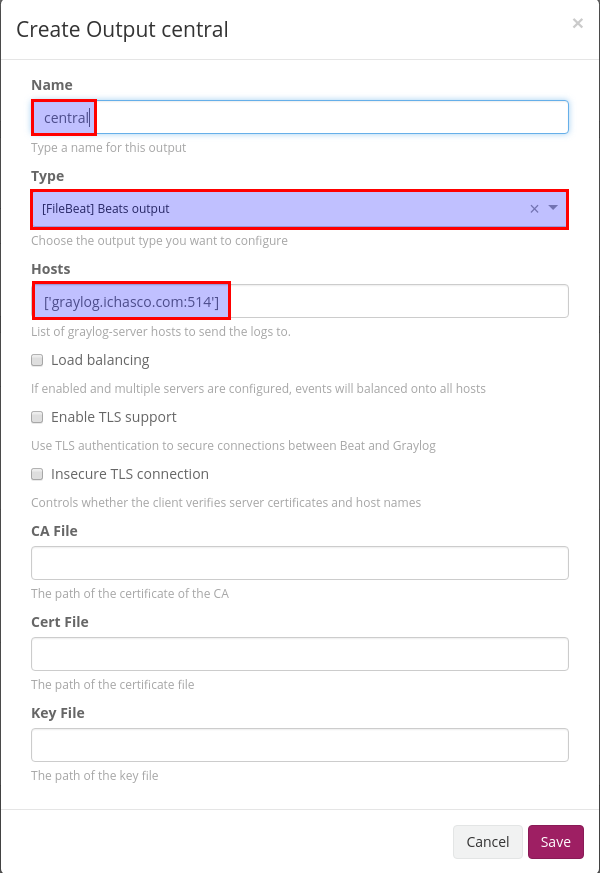
Una vez creado, solo queda el configurarlo. Para configurar el cliente, hay 2 partes principales. El input establece que logs se quieren recoger, si se quiere excluir o incluir algo de estos o si se quieren crear campos fijos y el output se encarga de configurar donde y como tiene que enviar el agente los logs.
Output


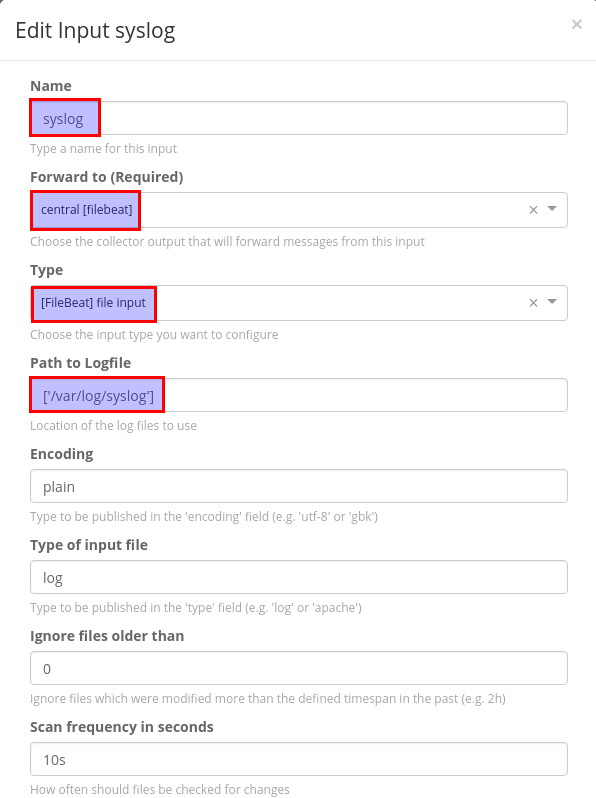
Input

![]()
Por último añadir el tag que hemos puesto en la configuración del agente y darle a update tag.
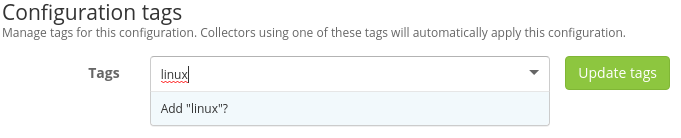
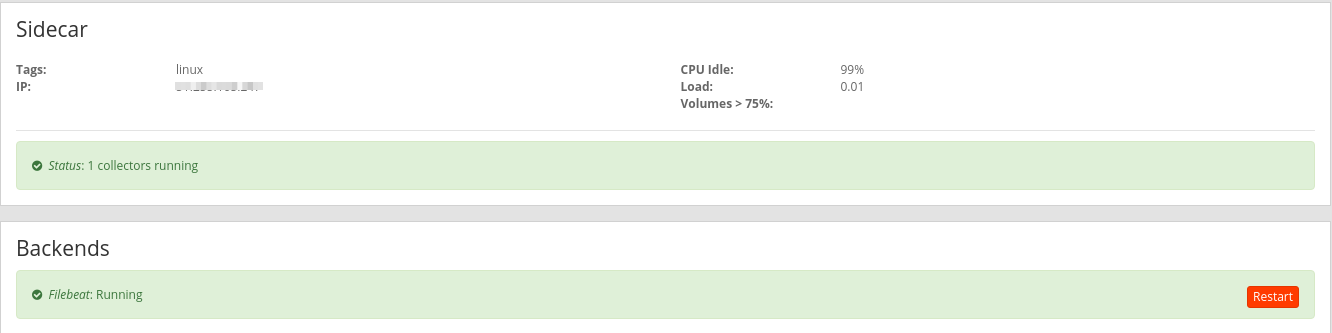
Y ya estaría funcionando. Ahora se puede comprobar en Overview que el agente está arrancado


Ahora se podría, tanto tratar los mensajes del agente como un input normal para poder crear streams o dashboard. O también se podría ver el estado del agente y los logs de la carpeta de logs definida en el agente. Si hubiese cambios en alguno de estos, se marcarían en azul.
Con esto, ya estaría el agente desplegado y recolectando logs.
Hola, excelente articulo, me podrias orientar para hacerlo en un cliente Windows Server 2008?
Saludos
Buenas Esteban,
no se si seguirás teniendo problemas o dudas con el cliente en Windows (he dejado este mes un poco el blog de lado y no me he podido meter). Sigues necesitando ayuda? si es así, podrías describirme que problema tienes?
Un saludo
Buenos días
Tengo un cacao con esta movida que lo flipo.
Vamos a ver, yo tengo un servidor que se llama graylog-server, una base de datos que es mongodb y tengo elasticsearch, con todo eso funcionando ¿que tengo que hacer para que me lleguen inputs al servidor graylog de las maquinas a monitorear?
Me imagino que lo que hay en el manual que has publicado pero ¿filebeat hace lo mismo?
¿logstash es lo mismo que collector-sidecar? osea el collector recolecta y el sidecar envía y los dos son el agente, ¿es eso?
Hay otro agente que se llama metricbeat que hace lo mismo que collector y el primero se lo manda a logstash y el segundo se lo manda a sidecar, y todo eso va a elasticsearch y/o al servidor, ¿es así?
saludos.
Buenas, el post este tiene ya algún tiempo. Han salido varias versiones nuevas de Graylog.
En cuanto a tu pregunta. Sin saber ahora muy bien si Graylog ha sacado algún nuevo componente, filebeat y el collector-sidecar es lo mismo. Son agentes que envían logs ya sea a graylog, a un logstash (con este servicio puedes recibir logs y tratarlos. Graylog es un logstash y un elasticsearch todo en uno) o a elasticsearch directamente.
En cuanto a metricbeat, es para recolectar las metricas y enviarselas a elasticsearch. Esto es para poder usar las funciones de APM de elastic.
El flujo en Graylog es (o era):
collector-sidecar –> Graylog –> Y ya puedes ver los logs
En el stack de elastic:
filebeat –> logstash –> opensearch –> kibana.
No se si esto te ayudará mucho xD