Buenas a todo@s. En este post, voy a explicar como desplegar un cluster en GKE con Terraform utilizando módulos. Además de esto, añadiremos un bonus que será crear un Dashboard automáticamente en Grafana.

Vamos por partes. ¿Que es GKE? GKE es Google Kubernetes Engine, es decir el sistema de Kubernetes de Google Cloud Platform. En este Post no vamos a hacer mucho hincapié en como funciona Kubernetes. De esto, posiblemente hable en post futuros.
Lo siguiente en la lista es Terraform. De esto si que vamos a hablar. Terraform es una herramienta de IaC. Y ¿Que es esto? pues una herramienta que hace que podamos definir la infraestructura que queremos desplegar como código. En este caso se define en HCL (HashiCorp Configuration Language).
Las ventajas de esto son muy potentes, ya que se puede versionar, permite mantener la infraestructura en un estado consistente (todos los cambios que se realicen y no estén en el código, se pueden deshacer fácilmente aplicando las definiciones) y tiene una lista bastante amplia de proveedores (GCP, AWS, HELM, Kubernetes…), También se puede reutilizar para diferentes proyectos.
Además de esto, vamos a realizar el despliegue, usando módulos. Que es muy recomendable el emplearlos, ya que nos da mucha mas versatilidad a la hora de gestionar los recurso definidos. Utilizando módulos, desde un mismo proyecto se pueden reutilizar para crear varios recursos sin tener que tocar la definición principal.
Empezamos
Crear el módulo
Primero tenemos que tener clara la jerarquía de carpetas que hay que utilizar. En este caso el proyecto se llamará Kubernetes_Project.
Kubernetes_Project
|---> main.tf
|---> variables.tf
|---> gke.tf
|---> modules
|---> gke
|---> main.tf
|---> variables.tf
|---> outputs.tf
|---> README.md
Por lo que vamos a empezar creando el árbol de directorios.
mkdir -p Kubernetes_Project/modules/gke
cd Kubernetes_Project/modules/gke
vim main.tfUna vez dentro de la carpeta del módulo que hemos creado, empezamos a definir la arquitectura. En nuestro caso va a ser una bastante simple. Definiremos lo siguiente:
- Nombre del Cluster
- Versión de Kubernetes
- Zona
- Ventana de mantenimiento
- Pool de nodos
- Auto-escaldao
- Auto-repair
- Auto-upgrade
- Sistema Operativo de los nodos
- Tamaño de disco de los nodos
- Tipo de máquina
- Preemtible
La primera parte, es el provider. Esto indica que usaremos google-beta, el proyecto donde vamos a desplegar todo y la región por defecto que vamos a utilizar. También se podría pasar el json del service-account para tener permisos, pero en este caso como lo vamos a lanzar todo una vez autenticados contra gcloud no hace falta.
https://www.terraform.io/docs/providers/google/index.html
provider "google-beta" {
project = "${var.project-id}"
region = "${var.region}"
}
resource "google_container_cluster" "gke-cluster" {
provider = "google-beta"
name = "${var.gke-name}"
description = "${var.description}"
min_master_version = "${var.gke-version}"
zone = "${var.gke-zone}"
additional_zones = ["${var.gke-additional-zones}"]
resource_labels {
project = "${var.project}"
stages = "${var.stages}"
}
node_pool {
name = "default-pool"
}
addons_config {
http_load_balancing {
disabled = "${var.gke-node-lb-disabled}"
}
horizontal_pod_autoscaling {
disabled = "${var.gke-node-pods-autoscaling-disabled}"
}
kubernetes_dashboard {
disabled = "${var.gke-node-dashboard-disabled}"
}
network_policy_config {
disabled = "${var.gke-node-network-policy-disabled}"
}
}
maintenance_policy {
daily_maintenance_window {
start_time = "03:00"
}
}
lifecycle {
ignore_changes = [ "node_count", "node_pool" ]
}
}
resource "google_container_node_pool" "gke-node-pool" {
name = "${var.gke-node-pool-name}"
cluster = "${google_container_cluster.gke-cluster.name}"
zone = "${var.gke-zone}"
node_count = "${var.gke-initial-node-count}"
autoscaling {
min_node_count = "${var.gke-autoscaling-min}"
max_node_count = "${var.gke-autoscaling-max}"
}
management {
auto_repair = "${var.gke-node-auto-repair-enabled}"
auto_upgrade = "${var.gke-node-auto-upgrade-enabled}"
}
node_config {
disk_size_gb = "${var.gke-node-disk-size}"
disk_type = "${var.gke-node-disk-type}"
image_type = "${var.gke-node-image}"
machine_type = "${var.gke-node-machine-type}"
preemptible = "${var.gke-node-preemtible-enabled}"
oauth_scopes = [
"https://www.googleapis.com/auth/compute",
"https://www.googleapis.com/auth/devstorage.read_only",
"https://www.googleapis.com/auth/logging.write",
"https://www.googleapis.com/auth/monitoring",
]
labels {
project = "${var.project_name}"
stages = "${var.stages}"
}
'
tags = ["k8s"]
}
}Variables
Ahora ya tenemos definida la infraestructura. Pero no tiene ningún valor, para ello hay que crear un fichero con las variables que se llame variables.tf. Estas variables, van a ser las “estándar” pero luego se pueden sobre-escribir cuando llamemos al módulo. Por lo que lo mejor, es dejarlas lo mas estándar posibles.
vim variables.tfvariable "project-id" {
type = "string"
description = "Project ID for GCP"
default = "Proyect"
}
variable "region" {
type = "string"
description = "GCP region"
default = "region"
}
variable "gke-name" {
type = "string"
description = "Name for GKE cluster"
default = "kubernetes-cluster"
}
variable "description" {
type = "string"
description = "description"
default = "Managed by Terraform"
}
variable "gke-version" {
type = "string"
description = "Version for GKE custer"
default = "1.11.6-gke.6"
}
variable "gke-zone" {
type = "string"
description = "Zone for GKE cluster"
default = "europe-west1-b"
}
variable "gke-additional-zones" {
type = "string"
description = "Additional Zones for GKE cluster"
default = "europe-west1-c"
}
variable "gke-node-pool-name" {
type = "string"
description = "GKE Node Pool Name"
default = "primary-pool"
}
variable "gke-initial-node-count" {
type = "string"
description = "GKE Initial node conunt per zone"
default = "2"
}
variable "gke-node-disk-size" {
type = "string"
description = "GKE Node disk size"
default = "100"
}
variable "gke-node-disk-type" {
type = "string"
description = "GKE Node disk type"
default = "pd-standard"
}
variable "gke-node-image" {
type = "string"
description = "GKE Node disk Operative System"
default = "COS"
}
variable "gke-node-machine-type" {
type = "string"
description = "GKE Node type"
default = "n1-standard-2"
}
variable "gke-node-preemtible-enabled" {
type = "string"
description = "GKE Node preemtible enabled"
default = "false"
}
variable "project_name" {
type = "string"
description = "Stage for GKE resources"
default = "kubernetes-project"
}
variable "stages" {
type = "string"
description = "Stage for GKE resources"
default = "production"
}
variable "gke-autoscaling-min" {
type = "string"
description = "Min GKE nodes"
default = "4"
}
variable "gke-autoscaling-max" {
type = "string"
description = "Max GKE nodes"
default = "6"
}
variable "gke-node-auto-repair-enabled" {
type = "string"
description = "Enable auto-repair in GKE nodes"
default = "true"
}
variable "gke-node-auto-upgrade-enabled" {
type = "string"
description = "Enable auto-upgrade in GKE nodes"
default = "true"
}
variable "gke-node-lb-disabled" {
type = "string"
description = "Disable LB in GKE nodes"
default = "true"
}
variable "gke-node-pods-autoscaling-disabled" {
type = "string"
description = "Disable autoscaling pods in GKE nodes"
default = "true"
}
variable "gke-node-dashboard-disabled" {
type = "string"
description = "Disable dashboard in GKE nodes"
default = "true"
}
variable "gke-node-network-policy-disabled" {
type = "string"
description = "Disable Network Policy in GKE nodes"
default = "true"
}Outputs
Ahora ya tenemos algo mas funcional. Lo único que nos quedaría sería definir el outputs. Lo que hace esto, es sacarte por pantalla el resultado de lo que le indiques.
vim outputs.tfoutput "gke_cluster_master_version" {
value = "${google_container_cluster.gke-cluster.master_version}"
}Con esto ya tendríamos el módulo listo. Ahora solo nos queda invocarlo. Para esto, hay que crear un fichero en la raíz del proyecto que lo haga. Lo llamaremos gke.tf. En este ejemplo, voy a dejar todas las variables que estamos utilizando en el módulo, pero las dejo comentadas. En el caso de que queráis sobre-escribir alguna de las definidas en el módulo, habría que hacerlo desde aquí. Las únicas 2 variables que voy a utilizar son la de project-id y region que son necesarias para definir el provider. Pero las dejo definidas con otra variable que indicaremos en el siguiente paso.
cd ../../
vim gke.tfmodule "gke" {
source = "./modules/gke"
project-id = "${var.project-id}"
region = "${var.region}"
# gke-name =
# description =
# gke-version =
# gke-zone =
# gke-additional-zones =
# gke-certificate-enabled =
# gke-node-pool-name =
# gke-initial-node-count =
# gke-node-disk-size =
# gke-node-disk-type =
# gke-node-image =
# gke-node-machine-type =
# gke-node-preemtible-enabled =
# project_name =
# stages =
# gke-autoscaling-min =
# gke-autoscaling-max =
# gke-node-auto-repair-enabled =
# gke-node-auto-upgrade-enabled =
# gke-node-lb-disabled =
# gke-node-pods-autoscaling-disabled =
# gke-node-dashboard-disabled =
# gke-node-network-policy-disabled =
}Una vez hecho esto, creamos el fichero de variables globales para el proyecto. Estas variables no afectan a los módulos a no ser que se le indique como hemos hecho antes. En este caso las variables a definir son: project-id y region. El project-id es el ID del proyecto en GCP, no el nombre. Y la region es la que usaremos por defecto.
vim variables.tfvariable "project-id" {
type = "string"
description = "GCP project ID"
default = "gcp-project-id"
}
variable "region" {
type = "string"
description = "GCP region for resources"
default = "europe-west1"
}Una vez hecho esto, ya seriamos capaces de desplegar la infraestructura. Pero por buenas prácticas, vamos a crear otro fichero que se llama main.tf donde vamos a indicar que el archivo que utiliza terraform para almacenar el estado de lo desplegado (default.tfstate) no esté en local. Si no que esté un un bucket. En este caso un storage de google. Para esto, hay que crear el storage manualmente y darle un nombre. “terraform-kubernetes” por ejemplo.
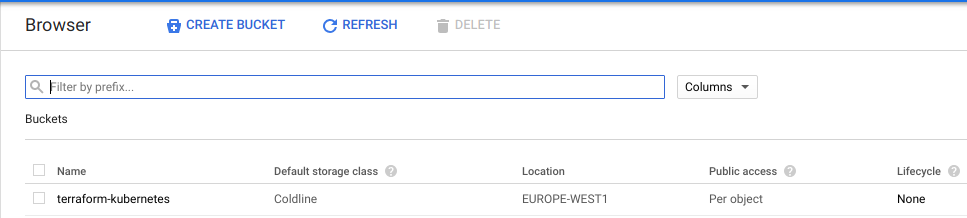
Y ahora definimos el main.tf
vim main.tfterraform {
backend "gcs" {
bucket = "terraform-kubernetes"
prefix = "production/terraform.tfstate"
}
}Despliegue
Con todo esto, ya podemos empezar a desplegar la infraestructura. Para esto, hay que inicializar el proyecto en terraform. Esto iniciará los plugins y los módulos.
terraform initInitializing modules...
- module.gke
Initializing the backend...
Initializing provider plugins...
The following providers do not have any version constraints in configuration,
so the latest version was installed.
To prevent automatic upgrades to new major versions that may contain breaking
changes, it is recommended to add version = "..." constraints to the
corresponding provider blocks in configuration, with the constraint strings
suggested below.
* provider.google-beta: version = "~> 1.20"
Terraform has been successfully initialized!
Una vez inicializado, ya podemos desplegar terraform con el comando terraform apply. Antes de aplicarse, nos mostrará todos los cambios que va a realizar y pedirá confirmación.
terraform applyY ya empezará a aplicar todos los cambios en GCP. Después de un rato, cuando termine, nos sacará por pantalla los outputs definidos, en este caso solo es uno.
Outputs:
gke_cluster_master_version = 1.11.6-gke.6
Bonus: Añadir un Dashboard en Grafana automáticamente
Como hemos comentado antes, vamos a hacer que además de generar el cluster de GKE, cree en nuestro grafana un dashboard. Aquí entra en juego el data source que empleemos, si es influx, prometheus… Como en el despliegue de GKE no se instala por defecto ninguno, vamos a crear un Dashboard a partir de una plantilla que se rellenará una vez se conecte el data source. Para esto, vamos a crear otro módulo. Por lo que el árbol de directorios quedará así:
Kubernetes_Project
|---> main.tf
|---> variables.tf
|---> gke.tf
|---> grafana.tf
|---> grafana.json
|---> modules
|---> grafana
| |---> main.tf
| |---> variables.tf
| |---> README.md
|---> gke
Lo primero es crear la carpeta del módulo y empezar con el main.tf. Este va a ser mucho mas sencillo que le de antes.
mkidir modules/grafana
cd modules/grafana
vim main.tfprovider "grafana" {
url = "${var.grafana-url}"
auth = "${var.grafana-auth}"
}
resource "grafana_dashboard" "metrics" {
config_json = "${file("${var.grafana-dashboard-json}")}"
}Ahora toca el de las variables.
vim variables.tfvariable "grafana-url" {
type = "string"
description = "Grafana URL"
default = "http://grafana.example.com"
}
variable "grafana-auth" {
type = "string"
description = "Grafana API Token"
default = "api-key"
}
variable "grafana-dashboard-json" {
type = "string"
description = "Grafana Dashboard JSON"
default = "grafana.json"
}Ahora tenemos que crear la API key desde grafana y exportar el Dashboard que vayamos a utilizar.
Para crear el API key, tenemos que ir a Configuration –> API keys –> +Add API key. Y crear una que se llame terraform. Es importante apuntar la Key ya que luego no se puede volver a consultar.

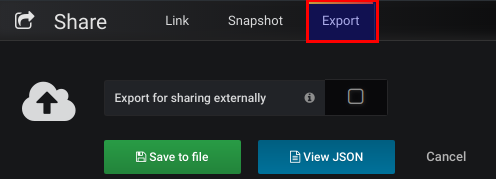
Nos queda exportar un dashboard para reutilizarlo. Para esto, hay que ir al dashboard en cuestión y darle a shared dashboard.

E ir a la pestaña de export y o bien descargar el archivo o bien copiarlo. En nuestro caso, vamos a necesitar un a archivo json que se llame grafana que estará en la raíz del proyecto.
Una vez hecho esto, ya podemos ir a crear el archivo que llame al módulo desde la raíz.
cd ../../
vim grafana.tfmodule "grafana" {
source = "./modules/grafana"
grafana-url = "http://grafana.example.com"
grafana-auth = "API KEY"
grafana-dashboard-json = "grafana.json"
}Y por último, solo queda iniciarlo y aplicar el terraform. Cuando se hace un apply se aplica todo lo que esté en el proyecto. Por lo que también se aplicará el de GKE. Pero al no haber cambiado nada, no debería de aplicarlo. En el caso de que solo se quiera aplicar un cambio en concreto se puede hacer con la opción de –target=module.grafana.
terraform initterraform applyY con esto ya tendremos el dashboard creado en grafana.
Con este mini-tutorial hemos podido ver como funciona los módulos y su utilidad. La idea de esto ir añadiendo providers para intentar automatizar el proceso de despliegue de infraestructuras. El siguiente paso, podría ser desplegar los contenedores con HELM.
Also published on Medium.